Scikit-learn 的管道(Pipeline)实现了对转换器(Transformer)和估计器(Estimator)的流式化封装和管理,本文以 wdbc 数据集 为例对其进行说明。
wdbc 数据集
wdbc 全称为威斯康星州的乳腺癌诊断(Wisconsin Diagnostic Breast Cancer),其中包含良性和恶性肿瘤细胞的样本共计 569 个。数据集为如下构成:
- 第 1 列:样本的唯一 ID 号
- 第 2 列:样本的诊断结果,M 表示恶性(malignant),B 表示良性(benign)
- 第 3~32 列:30 个已经从细胞核的数字化图像计算出的特征,用来预测肿瘤属于良性还是恶性
wdbc 数据导入见下节。
数据导入和预处理
读入 wdbc 数据集,并通过以下三个简单步骤分为训练集和测试集:
- 从 UCI 网站读取数据:
1 | import pandas as pd |
- 从第 3~32 列的特征构建 numpy 数组
X,并通过LabelEncoder将第 2 列的字符串转换为整数:
1 | from sklearn.preprocessing import LabelEncoder |
序列标签(诊断结果)编码后为 y,恶性肿瘤和良性肿瘤分别以 1 和 0 表示。
- 将数据集划分为 80% 的训练集和 20% 的测试集:
1 | from sklearn.model_selection import train_test_split |
管道类型的使用
按照如下步骤对数据进行分类:
- 标准化数据集
- 通过 PCA 将数据从 30 维降低到较低维度(二维)的子空间
- 通过线性分类器(逻辑回归)分类
相比于每一个步骤的分开实现,通过 scikit-learn 的类 sklearn.pipeline可以便捷地实现上述流程:
1 | from sklearn.preprocessing import StandardScaler |
make_pipeline 函数采用任意数量的 scikit-learn 转换器(支持拟合和变换方法的对象作为输入)和一个 scikit-learn 估计器结合,实现拟合和预测方法。
前面的代码中将两个转换器 StandardScaler、PCA,一个估计器 LogisticRegression 输入到 make_pipeline 中,构造了一个 sklearn.Pipeline 对象。调用管道类型的 fit 方法时,会按照封装的先后顺序处理。
下图说明了管道类型的处理流程:
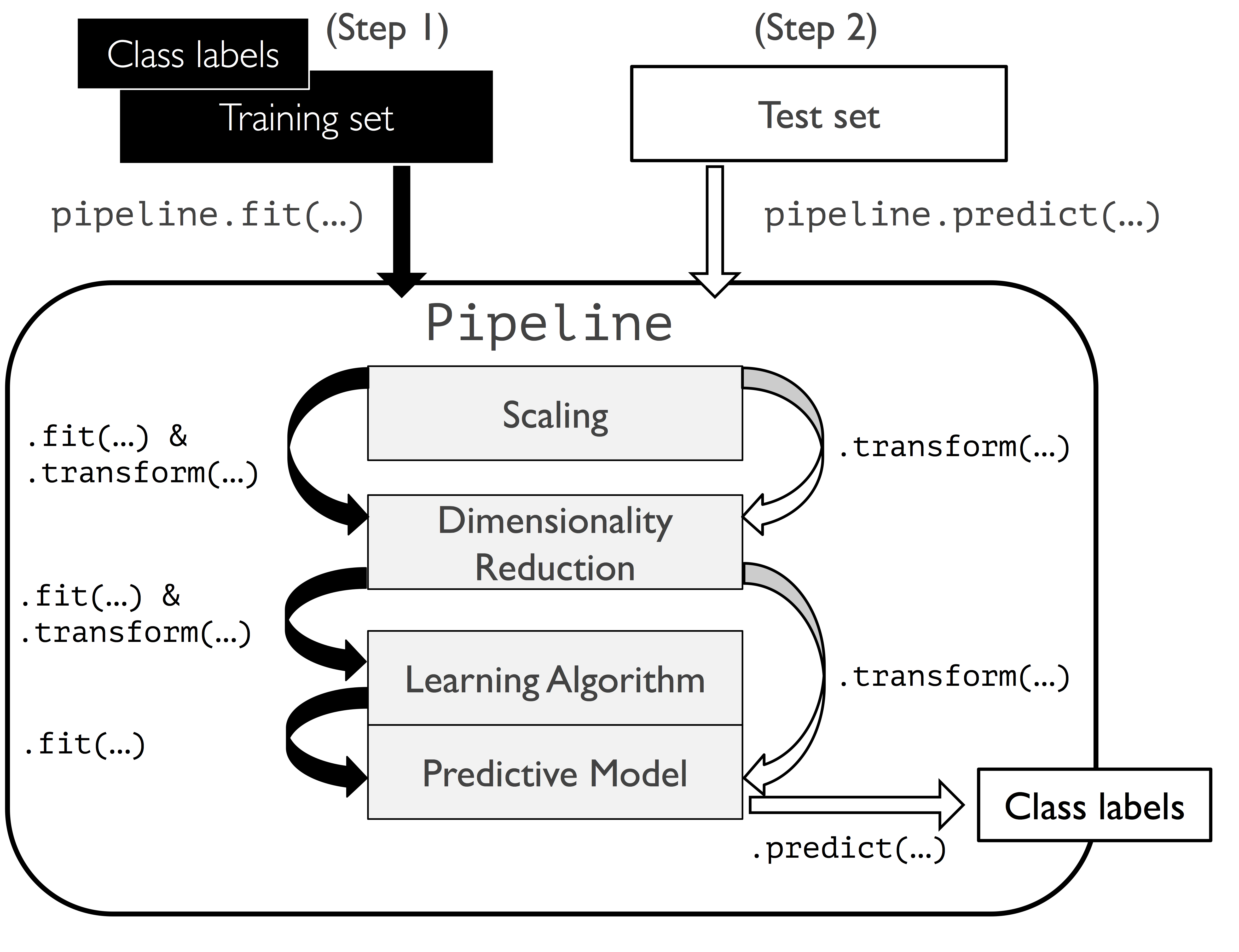
需要注意,管道中间转换器的数量没有限制,但最后一个管道的元素必须是估计器。
make_pipeline默认创建的参数是<estimator>__<parameter>形式(前者转换为小写,参数保持不变),如pca__n_components、svc__C,在网格搜索算法中需要用到。