K 折交叉验证(K-Fold Cross Validation)是一种模型选择(Model Selection)方法,将初始样本分为 K 个折叠(Fold),一个折叠作为数据集、其余 K-1 个折叠作为训练集,反复重复上述步骤 K 次并将得到的结果综合起来,得到最终的评估结果。
Holdout 验证
数据集划分:测试集和训练集
对于评估机器学习模型的泛化性能,一种经典和普遍的方法是 holdout 交叉验证。holdout 方法将初始数据集分成单独的训练集(Training Set)和测试集(Test Set),前者用于模型训练,后者用于评估模型的泛化性能。在典型的机器学习程序中,人们会对超参数进行不断调整和比较,以进一步提高对不可见数据进行预测的性能。这个过程被称为模型选择(Model Selection),尝试将超参数调整至最优。
但是,如果在模型选择过程中重复使用相同的测试集,那么这个测试集就不是真正意义上的测试集。真正的测试集应该是不可见的。如果一直尝试对测试集拟合,这个测试集实际上就是训练集的一部分。
尽管如此,许多人仍然将数据集分为测试集和训练集,然后按照测试集的表现来进行模型选择。这不是一个良好的机器学习方法。
数据集划分:测试集、验证集和训练集
一种更好的模型选择方法是将数据分成三部分:训练集、验证集(Validation Set)和测试集。训练集用于拟合不同的模型,然后根据模型在验证集上的表现来进行模型选择。在整个训练过程中,测试集是不可见的,不会对测试集过拟合。
下图说明了保持交叉验证的概念,使用训练集和验证集进行反复训练并将超参数调整至较优水平,再使用测试集来评估模型的泛化性能:
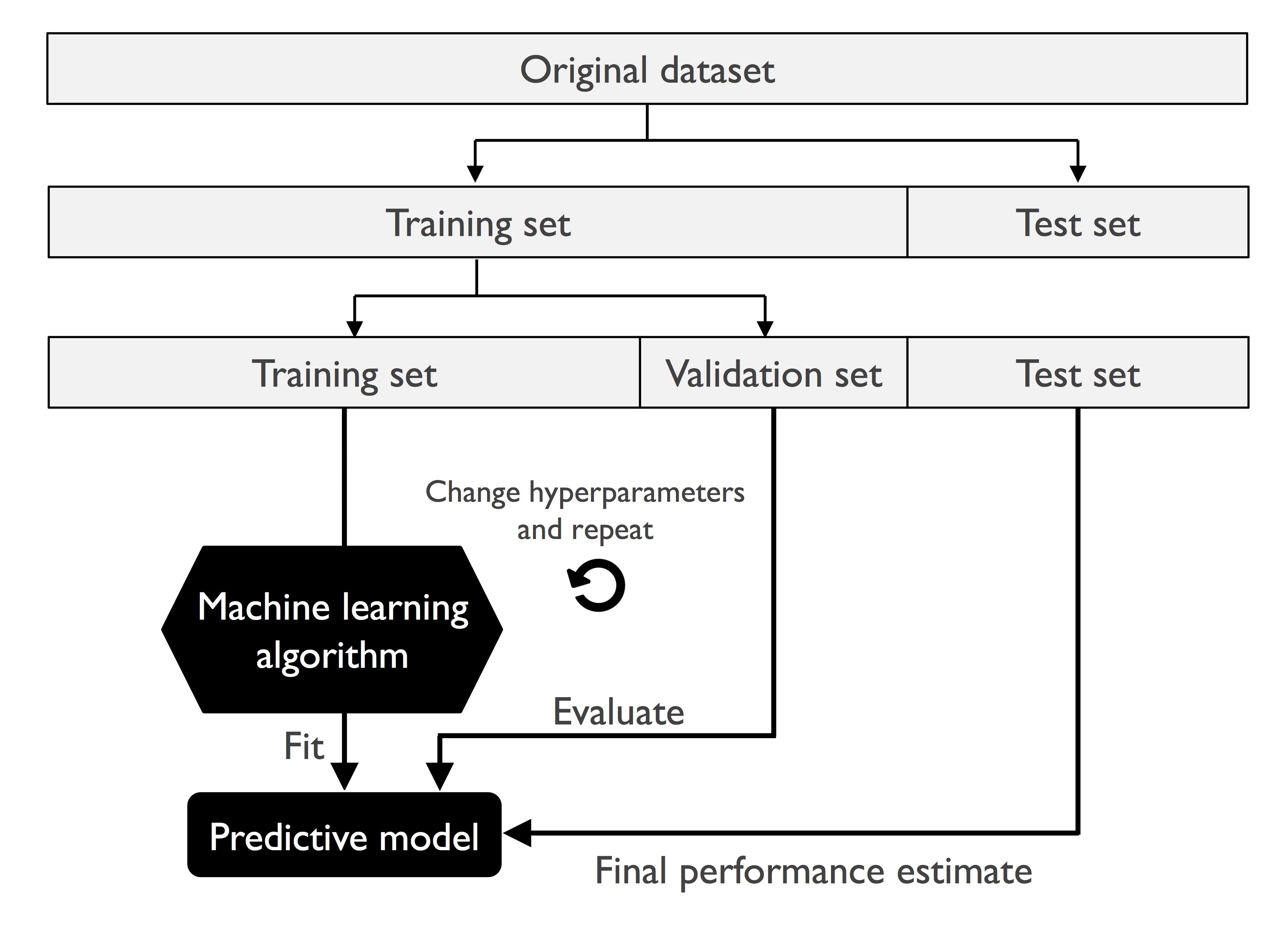
holdout 方法的缺点是算法评估对数据划分非常敏感,对于不同的数据划分比例和不同的分布,评估结果可能会有较大差异。
K 折交叉验证
K 折交叉验证的步骤是,随机地将训练数据集分成 K 次折叠。其中 K-1 次折叠用于模型训练、另外一个折叠用于性能评估,上述步骤重复 K 次(每次抽取不同的折叠),获得 K 个模型的性能评估结果。
K 折交叉验证可以得到令人满意的泛化性能的最优超参数值,具有更高的准确率和鲁棒性。K 折交叉验证表现好的原因在于其拥有更多的训练样本,且每个训练样本都恰好验证一次,这样可以产生较低的方差。
下图说明了详细的 K 折交叉验证(K = 10)的流程,其中 test fold 实际上发挥的是验证集的作用:
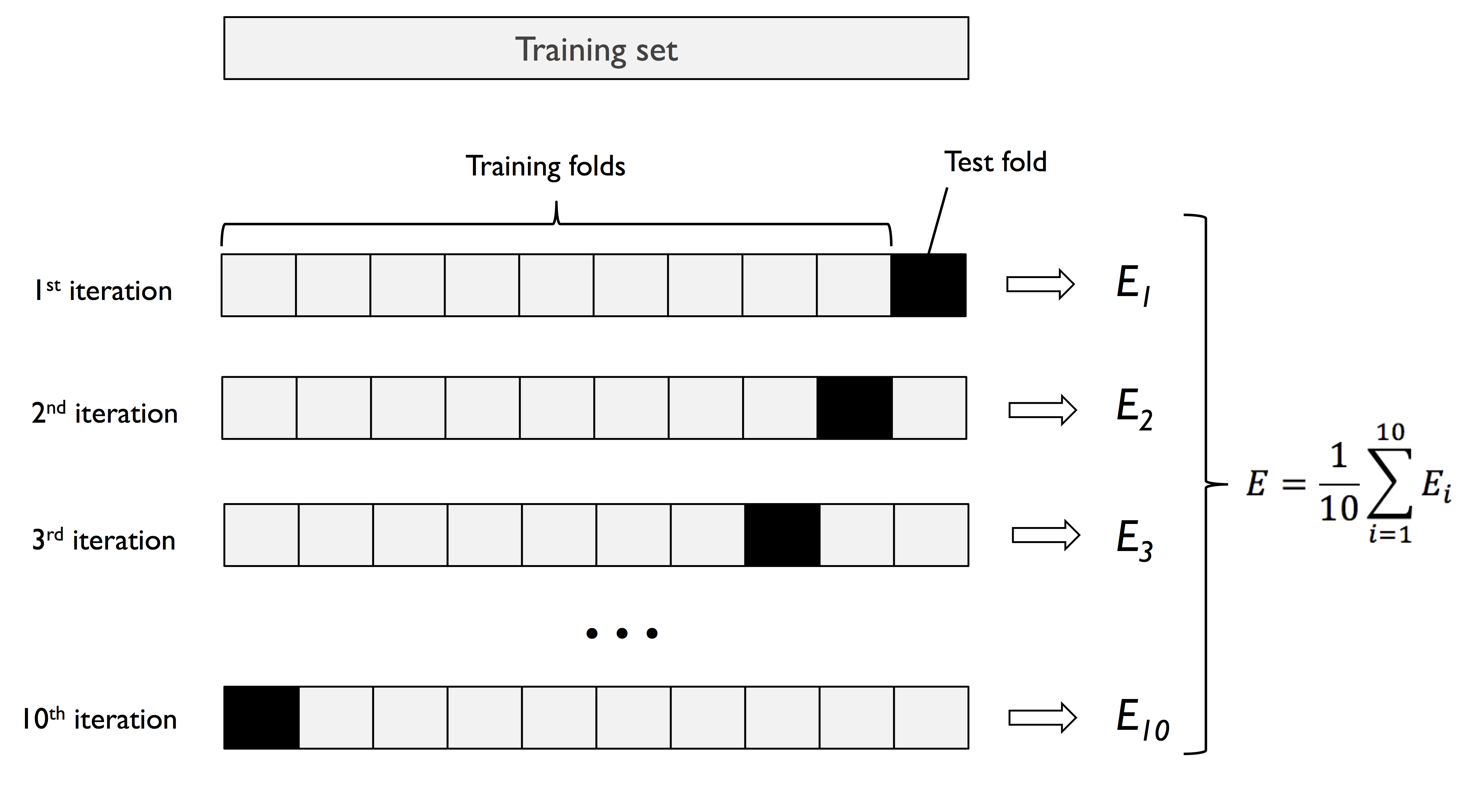
根据以往研究人员的经验,超参数 K 一般推荐采用 10。如果 K 太小,方差会较高,如果 K 太大,模型的训练时间会变长。对于大型数据集,可以适当降低 K 的值(如 K = 5)。
一种特殊的 K 折交叉验证为留一验证(Leave-One-Out Cross-Validation, LOOCV),K = n(n 为数据集的样本数量),每折只有一个样本,可以用于处理小数据集。
分层 K 折交叉验证的 scikit-learn 实现
分层 K 折交叉验证(Stratified K-Fold Cross-Validation)是对 K 折交叉验证的改进,分层的意思是每一个折叠中的分类比例都与原始数据集相同,能更好地适用于不同分类的样本数差异较大的情况。下面基于 scikit-learn 中的进行说明。
先做好交叉验证之前的前提工作,其中 pipe_lr 是管道对象,封装了标准化、PCA 和逻辑回归:
1 | import pandas as pd |
使用 sklearn.model_selection.StratifiedKFold 进行 K 折分层交叉验证:
1 | import numpy as np |
将样本分为 n_splits=10 个折叠,在每一次循环中使用管道对象 pipe_lr 对测试集进行训练,然后观察训练后的模型在验证集上的准确率。运行结果如下:
1 | Fold: 1, Class dist.: [256 153], Acc: 0.935 |
计算 10 次训练的准确率的平均值和方差:
1 | print('CV accuracy: {:.3f} +/- {:.3f}'.format(np.mean(scores), np.std(scores))) |
上面是通过具体实现流程说明交叉验证的工作流程,也可以通过 sklearn.model_selection.cross_val_score 实现模型评估:
1 | scores = cross_val_score(estimator=pipe_lr, X=X_train, y=y_train, cv=10, n_jobs=1) |
其中 cv 为折叠数量,n_jobs 是代码运行使用 CPU 核心的数量,结果如下:
1 | CV accuracy scores: [ 0.93478261 0.93478261 0.95652174 0.95652174 0.93478261 0.95555556 |
结果与之前一致,采用 cross_val_score 可以非常便捷地对交叉验证模型进行评估。
嵌套交叉验证
嵌套交叉验证(Nested Cross Validation)算法具有更稳定的性能,在训练集上的结果相对于测试集几乎是无偏的。
其思想是先使用 K 折交叉验证将数据分为训练折叠和测试折叠,然后在训练折叠内部使用 K 折交叉验证后用于测试折叠,以选择最优模型。如下为 5×2 折叠交叉验证的示意图:
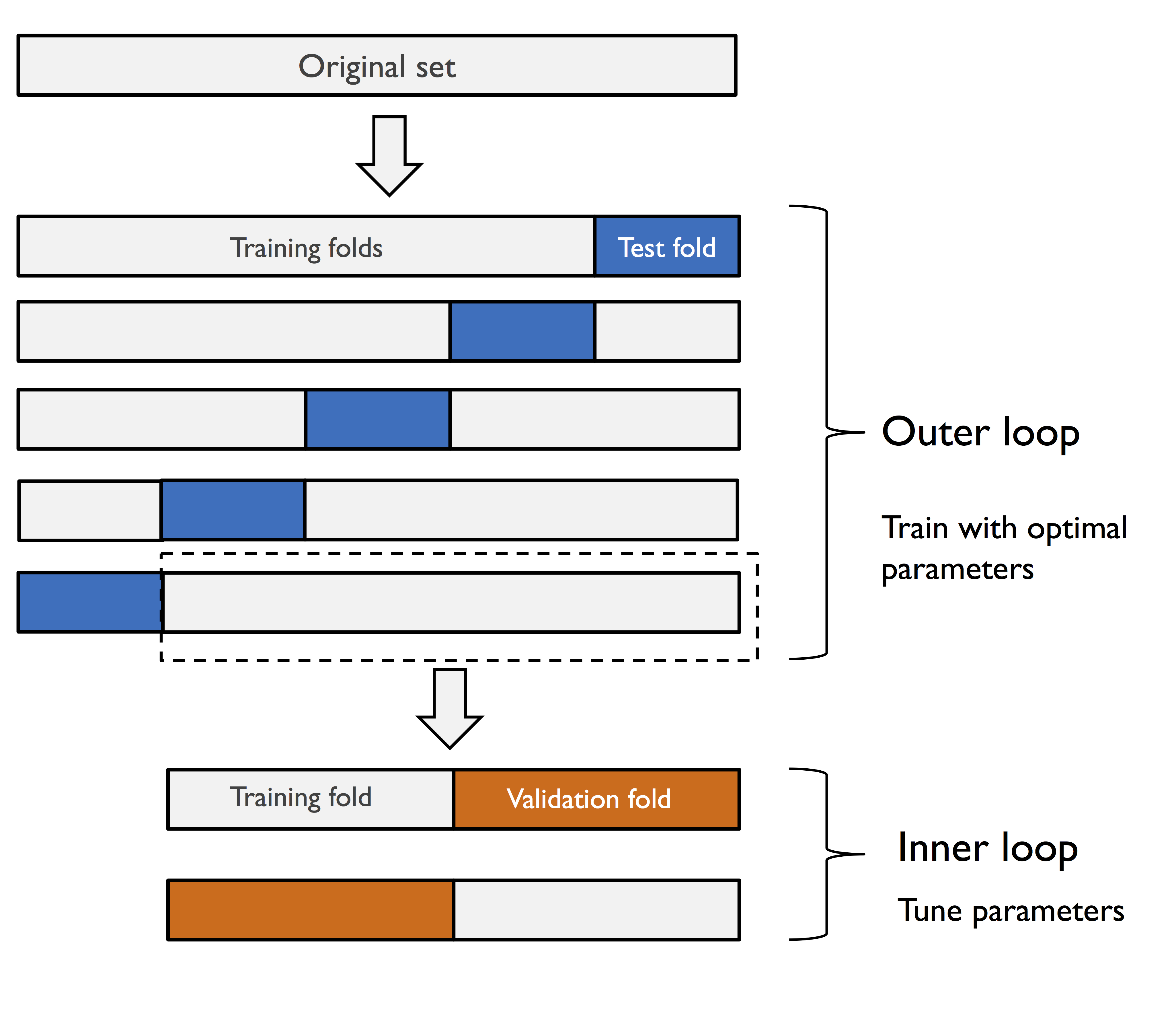
基于 SVM 的 5×2 折叠交叉验证,实现如下:
1 | gs = GridSearchCV(estimator=pipe_svc, param_grid=param_grid, scoring='accuracy', cv=2) |
基于决策树的 5×2 折叠交叉验证,实现如下:
1 | from sklearn.tree import DecisionTreeClassifier |
可以看到,基于 SVM 模型的嵌套交叉验证相比于基于决策树的交叉验证更优。