线性判别分析(Linear Discriminant Analysis,LDA)作为一种特征提取技术,可以提高计算效率,防止由于维数灾难而导致的过拟合。
LDA 与 PCA 类似,不同之处在于 PCA 的目标是找到数据集中最大方差的正交分量轴,而 LDA 的目标是找到优化类可分性的特征子空间。
LDA 和 PCA 都是线性变换技术,可用于减少数据集中的维数。区别在于 LDA 是监督算法,而 PCA 是无监督算法。
LDA 旨在找到对应最多投影的线性判别,如下图所示,其中圆形和十字分别表示两类的正态分布样本:
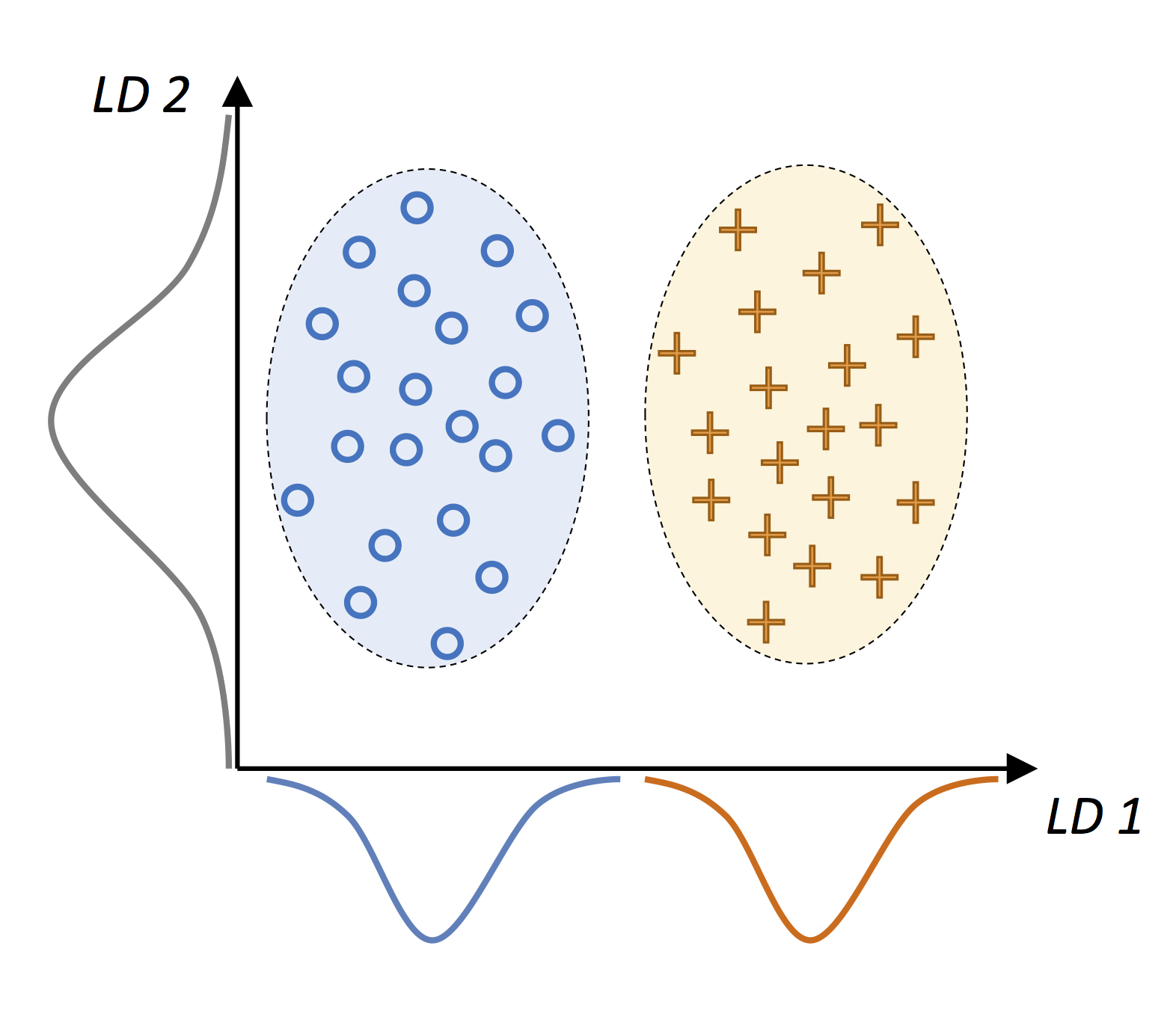
$x$ 轴(LD1)所示的线性判别可以很好地分类;而尽管 $y$ 轴(LD2)所示的线性判别拥有更大的投影方差,但是无法捕获任何分类信息。
LDA 中假设数据是正态分布的。此外,我们假设类的协方差矩阵相同,并且特征之间互不相关。
算法思想
LDA 的算法流程的简单介绍如下:
- 对输入的 $d$ 维数据集 $\boldsymbol X$ 进行标准化。
- 计算每个类的 $d$ 维均值向量,构造类内散布矩阵 $\boldsymbol S_W$ 和类间散布矩阵 $\boldsymbol S_B$。
- 计算矩阵 $\boldsymbol S_W^{-1} \boldsymbol S_B$ 的特征向量和特征值。
- 对特征值进行降序排序,对相应的特征向量进行排序。
- 提取 $k$ 个最大特征值对应的特征向量,其中 $k$ ($k \le d$) 是新特征子空间的维数。
- 使用提取的 $k$ 个特征向量构造投影矩阵 $\boldsymbol W$。
- 使用投影矩阵 $\boldsymbol W$ 对 $\boldsymbol X$ 进行变换,得到新的 $k$ 维特征子空间。
LDA 与 PCA 非常相似,通过将矩阵分解成特征值和特征向量,然后通过投影矩阵得到新的低维特征空间。其不同点在于 LDA 将类标签考虑在内(步骤 2)。
数据导入和标准化
导入 Wine 数据集 ,第 1 列为其分类标签,第 2~14 列为特征。分割数据集为 70% 的训练集和 30% 的测试集:
1 | import pandas as pd |
对训练集和测试集进行标准化:
1 | from sklearn.preprocessing import StandardScaler |
散布矩阵的构造
均值向量
计算均值向量,后面将用它来构造类内散布矩阵和类间散布矩阵。在第 $i$ 类样本的均值向量为 $\boldsymbol m_i$中,存储了该类样本特征的平均值 $\mu_m$:
$$\begin{align} \boldsymbol m_i = \frac 1 {n_i} \sum_{x \in D_i}^c \boldsymbol x_m \end{align}$$得到三个均值向量:
$$\begin{align} \boldsymbol m_i = \begin{bmatrix} \mu_{i,alcohol} \\ \mu_{i,malic \ acid} \\ \vdots \\ \mu_{i,proline} \end{bmatrix} \end{align}$$1 | np.set_printoptions(precision=4) |
类内散布矩阵
类内散布矩阵 $\boldsymbol S_W$ 的计算如下,其中 $\boldsymbol S_i$ 为第 $i$ 类的散布矩阵。
$$\begin{align} \boldsymbol S_W & = \sum_{i=1}^c \boldsymbol S_i \\ \boldsymbol S_i & := \frac 1 {n_i} \boldsymbol S_i = \frac 1 {n_i} \sum_{x \in D_i}^c (\boldsymbol x - \boldsymbol m_i) (\boldsymbol x - \boldsymbol m_i)^T = \boldsymbol \Sigma_i \end{align}$$由于 LDA 假设是训练集中的类别标签是均匀分布的,这里将散列矩阵 $\boldsymbol S_i$ 缩放至 $\frac 1 {n_i}$,缩放后恰好为协方差矩阵。
1 | d = 13 # number of features |
类间散布矩阵
类间散布矩阵 $\boldsymbol S_B$ 的计算如下,其中 $\boldsymbol m$ 为所有样本的均值向量:
$$\begin{align} \boldsymbol S_B = \sum_{i=1}^cn_i (\boldsymbol m_i - \boldsymbol m) (\boldsymbol m_i - \boldsymbol m)^T \end{align}$$1 | mean_overall = np.mean(X_train_std, axis=0) |
特征值和特征向量
计算矩阵 $\boldsymbol S_W^{-1} \boldsymbol S_B$ 的特征值和特征向量,按照特征值降序对相应的特征向量进行排序:
1 | eigen_vals, eigen_vecs = np.linalg.eig(np.linalg.inv(S_W).dot(S_B)) |
在 LDA 中,线性判别式的数目至多为 $c-1$,其中 $c$ 为类标签的数量。
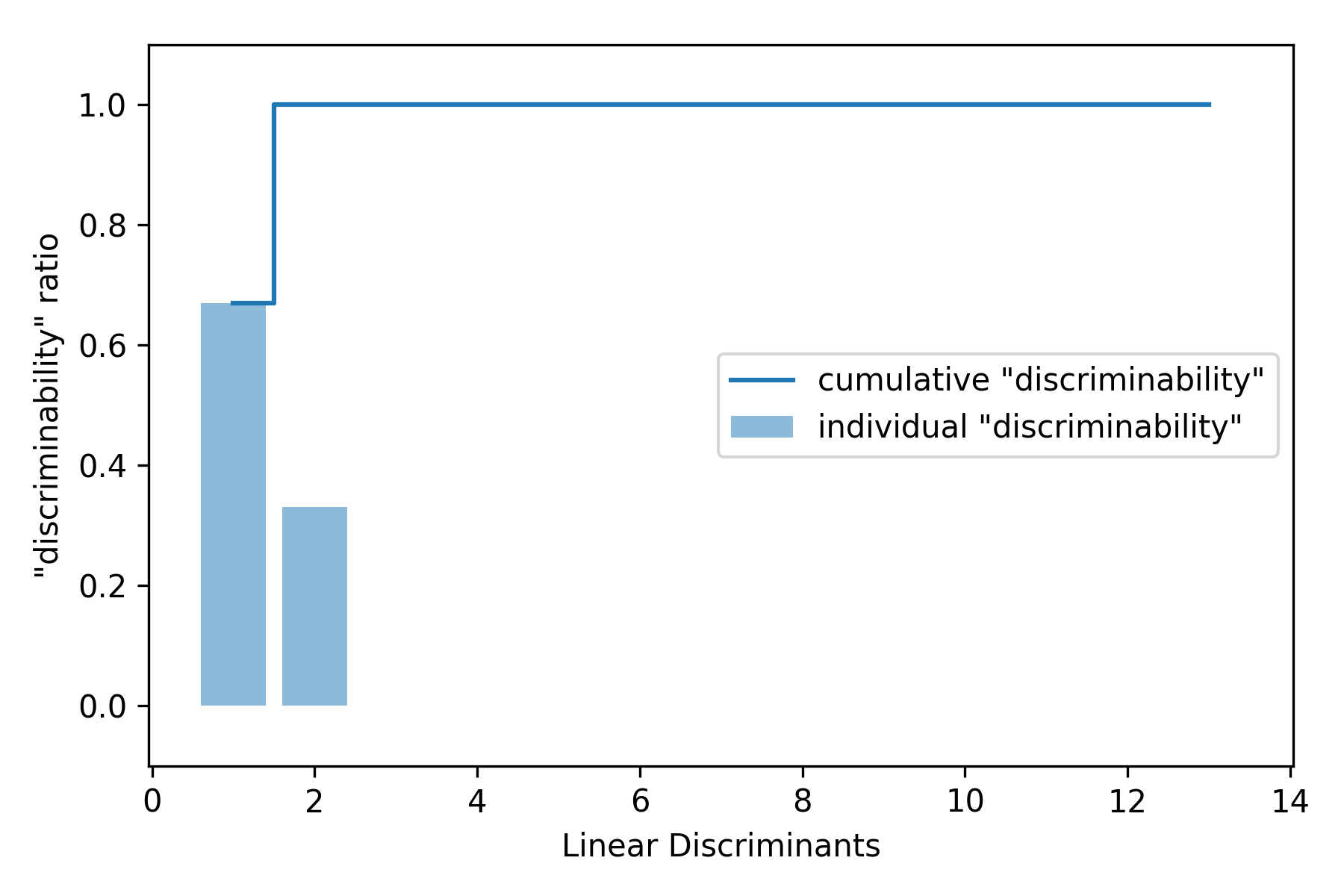
线性判别式的辨别能力
为了衡量线性判别式(特征向量)捕获多少类别鉴别信息,对不同的线性判别式的辨别能力(discriminability)进行绘图:
1 | import matplotlib.pyplot as plt |
特征提取
使用投影矩阵转换原始数据集:
$$\begin{align} \boldsymbol x' & = \boldsymbol x \boldsymbol W \\ & \downarrow \\ \boldsymbol X' & = \boldsymbol X \boldsymbol W \end{align}$$1 | w = np.hstack((eigen_pairs[0][1][:, np.newaxis].real, eigen_pairs[1][1][:, np.newaxis].real)) |
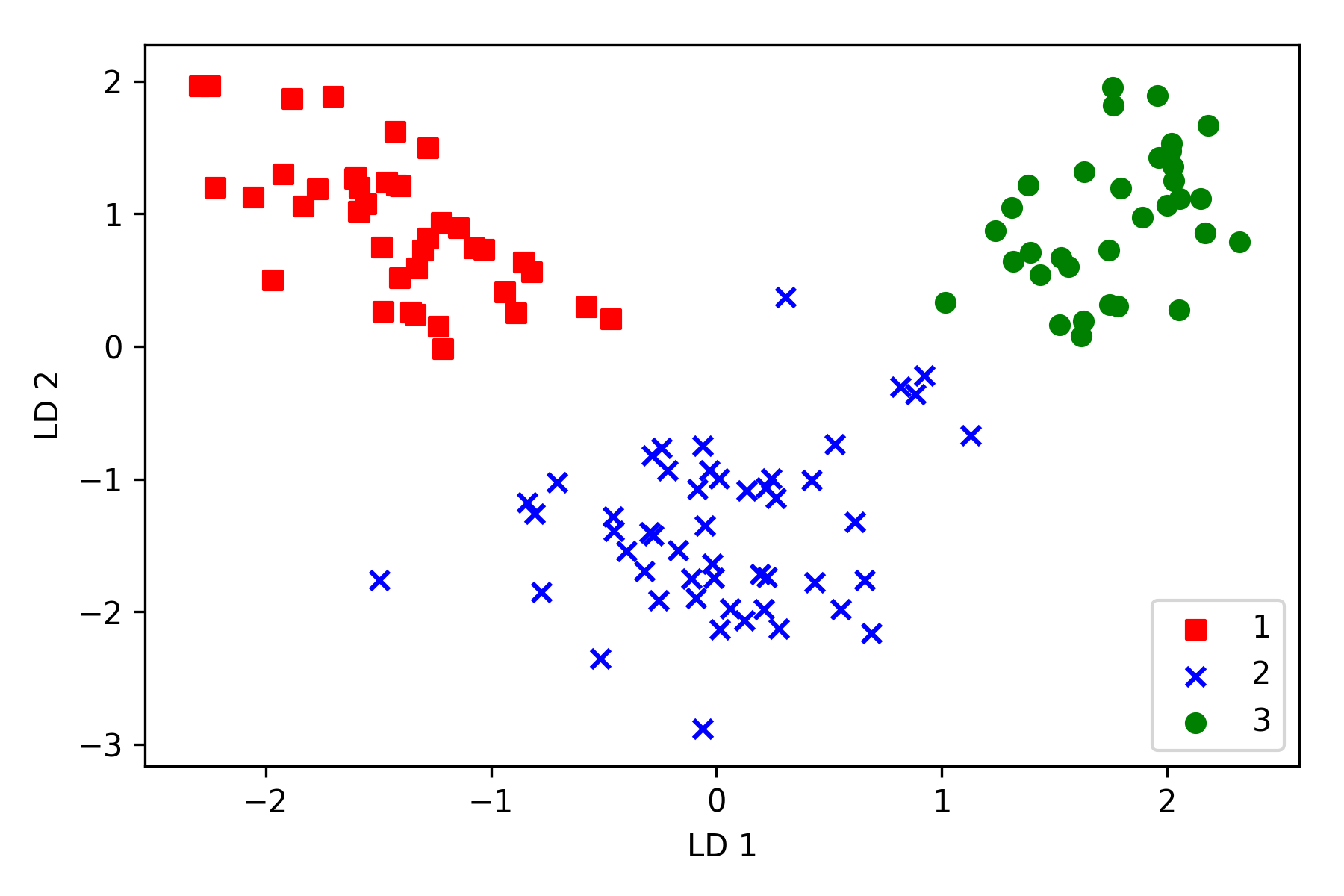
代码绘图结果如下,类别在新的特征子空间中线性可分:
Scikit-learn 实现
边界绘图函数
plot_decision_regions见之前的文章。
通过 sklearn.discriminant_analysis.LinearDiscriminantAnalysis 将测试集和训练集降至二维,然后使用逻辑回归对降维后的测试集进行线性分类:
1 | from sklearn.linear_model import LogisticRegression |
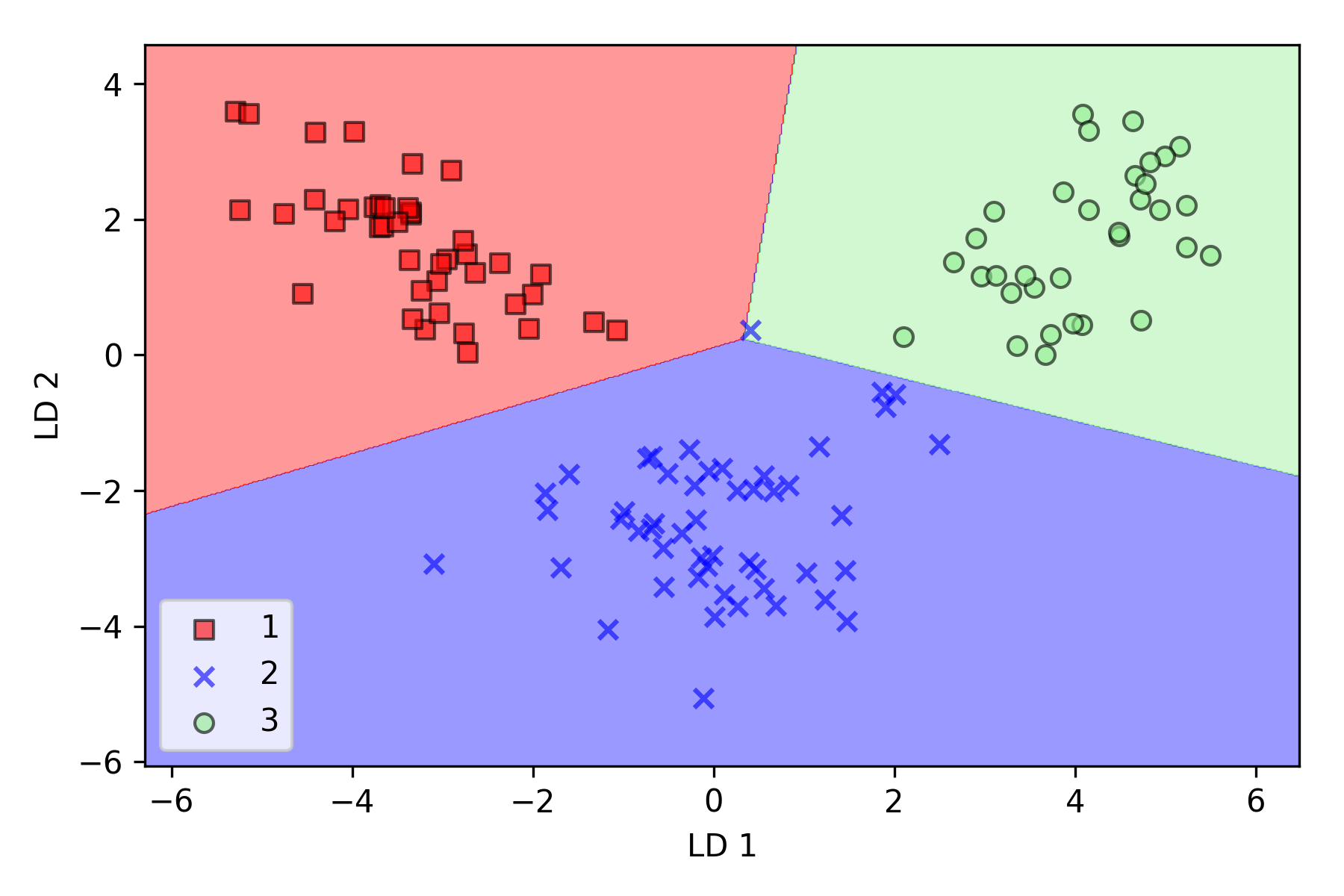
在降维空间绘制已通过训练得到的决策边界,观察是否能够进行很好地分类:
1 | plot_decision_regions(X_test_lda, y_test, classifier=lr) |
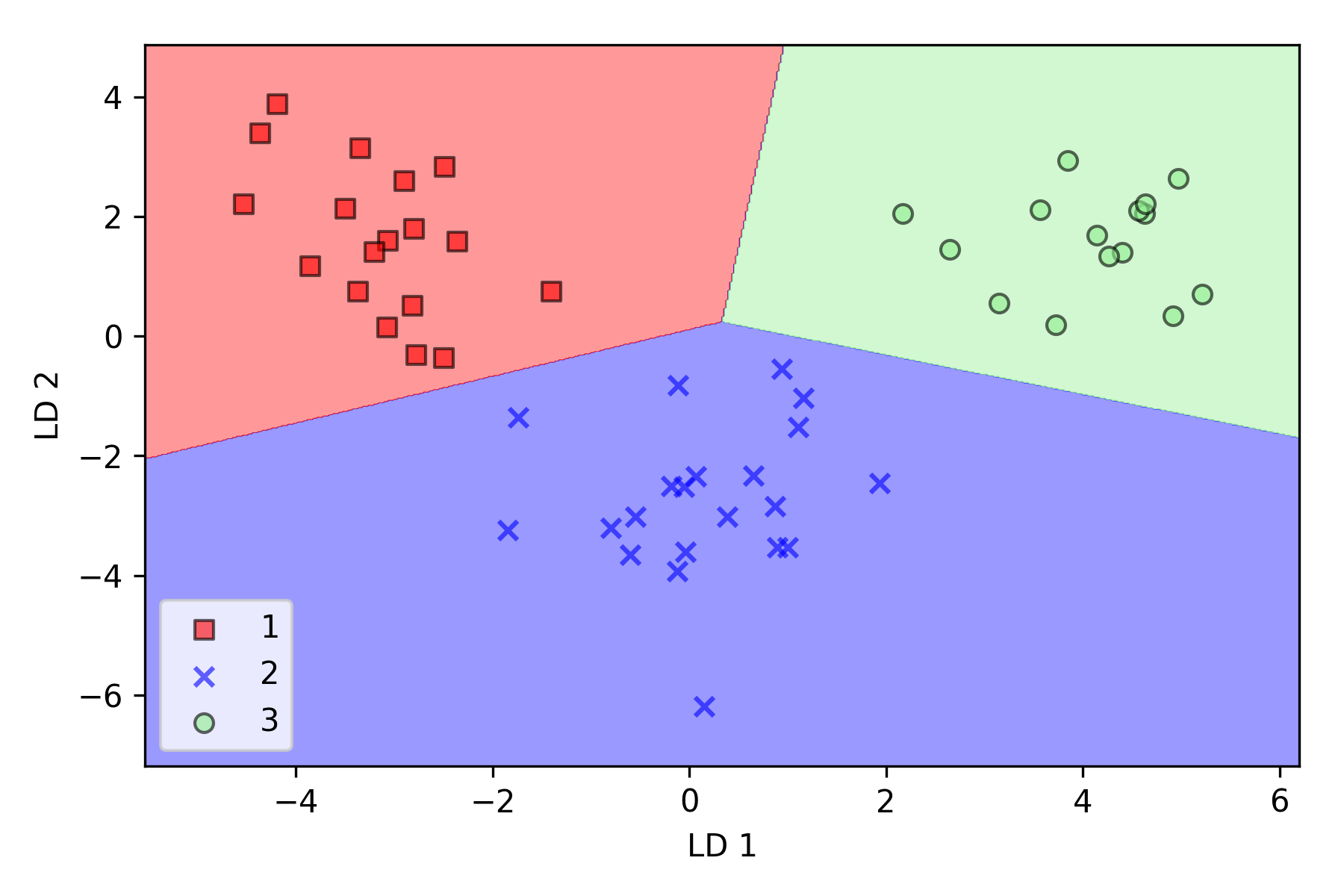
可以看到逻辑回归在新的二维子空间上表现很好,在测试数据集上只有很少样本分类错误。