欠拟合(Underfitting)和过拟合(Overfitting)是机器学习中的重要概念和常见问题。本文就这两个概念进行简单说明。
泛化
机器学习的目的,是利用已知数据(训练数据)训练出机器学习的模型,然后将该模型应用到未知数据(测试数据)中。
从已知数据归纳总结,然后对未知数据的预测称为泛化(Generalize)。
泛化能力好的机器学习模型,在使用训练数据进行训练后,对没有见过的数据可以进行准确预测。反之,泛化能力差的模型不能对未知数据进行准确预测。
拟合
过拟合和欠拟合都会导致模型没有良好的泛化能力。
以二维数据的二分分类为例,如下图:
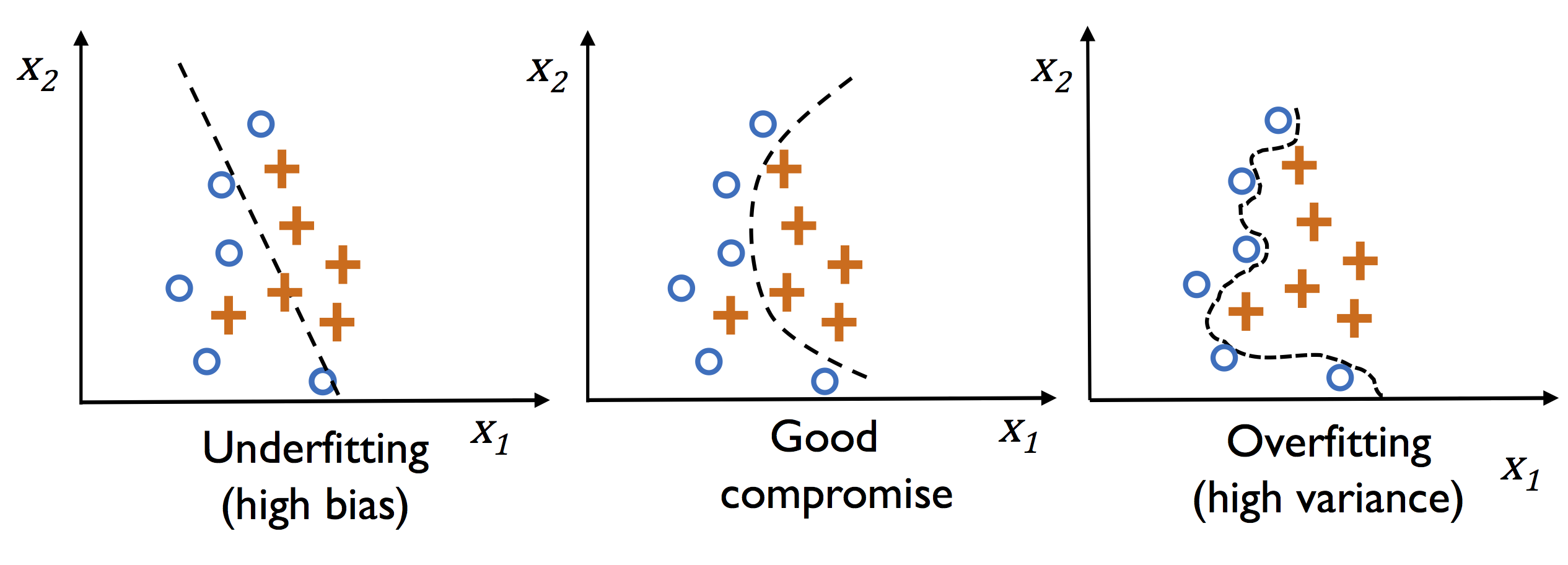
- 左子图:对已知数据欠缺拟合,存在高偏差(high bias)
- 右子图:对已知数据过度拟合,存在高方差(high variance)
- 中间子图:对已知数据良好拟合,可以概括出已知数据的特征
欠拟合
欠拟合的模型存在高偏差,对于已知数据和未知数据都表现不佳。
在机器学习中一般较少讨论欠拟合。一般而言,增加模型复杂度即可解决欠拟合问题。
过拟合
过拟合的模型存在高方差,对已知数据表现良好,但是对未知数据表现不佳。
过拟合表示对已知数据进行了过度解读,包括其中的噪音和细节,导致训练出来的模型不能很好地适用于未知数据。
样本数量少、噪音数据多、模型参数过多和复杂度过高等原因,都会导致过拟合。