本文对 TensorFlow 相关概念和安装流程(基于 Windows 操作系统)进行介绍,并说明了 GPU 适用于机器学习的原因。
2018 年 1 月 27 日,更新 TensorFlow GPU 1.5.0 的安装教程(基于 CUDNN 7 和 CUDA 9)。
什么是 TensorFlow
TensorFlow 是一个可扩展的多平台编程软件,用于实现和运行机器学习算法,并且方便对深度学习算法的封装。TensorFlow 最初由 Google Brain 团队的研究人员和工程师开发,最初仅限于内部使用,后续在 2015 年 11 月开源。
为了提高训练机器学习模型的性能,TensorFlow 允许在 CPU 和 GPU 上运行。和 CPU 相比,使用 GPU 时可以得到非常强大的性能,目前 TensorFlow 官方支持使用 CUDA 的 NVIDIA GPU。
TensorFlow 目前支持多种编程语言的接口,其中的 Python API 是最完善的 API。
TensorFlow 计算依赖于构造有向图来表示数据流。尽管构建图表听起来很复杂,但 TensorFlow 配备了高级 API,使其变得非常简单。
为什么使用 TensorFlow
一方面,Python 存在解释器锁(Global Interpreter Lock, GIL),它确保任何时候都只有一个 Python 线程执行。GIL 最大的问题就是 Python 的多线程程序并不能利用计算机硬件多核心的优势。
另外一方面,机器学习领域的快速发展,很大程度上受益于目前 GPU 的快速发展。下图为 Intel CPU (i7-6900k) 和 NVIDIA GPU (GTX 1080 Ti) 的性能比较:
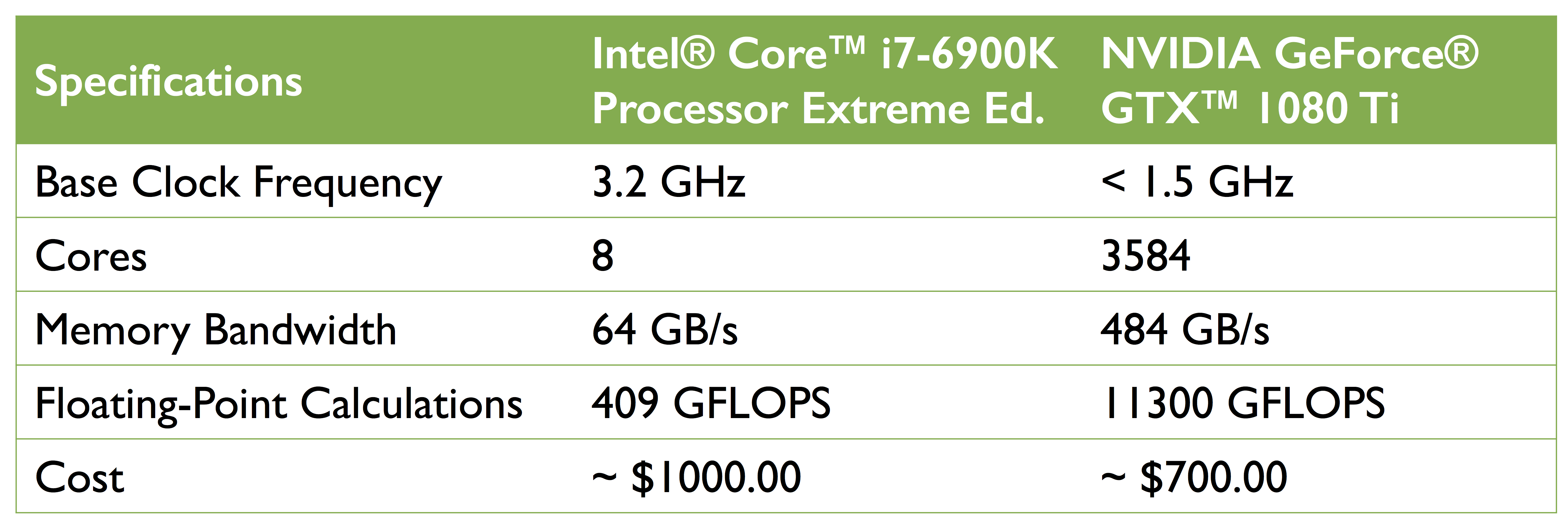
数据来源自:
- https://www.intel.com/content/www/us/en/products/processors/core/x-series/i7-6900k.html
- https://www.nvidia.com/en-us/geforce/products/10series/geforce-gtx-1080-ti/
在价格相当于 CPU 70% 左右的情况下,GPU 具有 450 倍的核心数 ,并且每秒可以执行大约 15 倍的浮点计算。
相对而言,使用 NVIDIA CUDA 等软件编写 GPU 代码来完成机器学习任务,并没有 Python 代码那么简单。
TensorFlow 对基于 GPU 的机器学习提供了强大高效的支持(目前只支持 NVIDIA CUDA,未来可能支持 OpenCL)。
Windows 安装
在 Windows 操作系统上安装 TensorFlow 之前,请确认完成以下步骤:
- 操作系统:64 位的 Windows 7 / Windows 10
- 安装 Git Windows 64-bit
- 安装 Python 3.6.x Windows 64-bit
- 安装 Visual C++ 2017
Python 扩展包
下载 whl 文件
前往 Python Libs 下载安装常用的 Python 软件库:
- Numpy+MKL :进行科学计算所需的基本软件包 + Intel® Math Kernel Library
- SciPy :数学工具包
- Matplotlib :绘图工具包
- Scikit-learn :机器学习软件包
务必注意,whl 安装文件需要以
cp36-cp36m-win_amd64.whl或py3-none-any.whl结尾。
安装 whl 文件
在 Git Bash 中输入 pip3 install *.whl 安装:以 Numpy+MKL 为例:
1 | $ pip3 install numpy‑*+mkl‑cp36‑cp36m‑win_amd64.whl |
安装 TensorFlow CPU
下载 tensorflow-1.5.0-cp36-cp36m-win_amd64.whl 并通过 pip3 install 安装。
安装 TensorFlow GPU
在安装 TensorFlow GPU 之前,请确保拥有 支持 CUDA 的 NVIDIA GPU 。
-
下载并安装 CUDA Toolkit 9.0 。
-
下载并安装 cuDNN v7.0.5 for CUDA 9.0 (需要注册 NVIDIA 账号)。
- 解压安装包至路径
<unzippath> - 拷贝
<unzippath>\cuda\bin\cudnn64_6.dll至C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\bin目录 - 拷贝
<unzippath>\cuda\include\cudnn.h至C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\include目录 - 拷贝
<unzippath>\cuda\lib\x64\cudnn.lib至C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\lib\x64目录
- 下载 tensorflow_gpu-1.5.0-cp36-cp36m-win_amd64.whl 并通过
pip3 install安装。
判断 TensorFlow 版本
通过 tf.__version__ 打印当前使用的 TensorFlow 版本:
1 | import tensorflow as tf |
支持 GPU 的 TensorFlow 配置
下文的代码运行基于机器配置 Intel i5-4590 CPU + NVIDIA GeForce GTX 1060 6GB。
支持设备
TensorFlow 支持的设备类型是 CPU 和 GPU。 他们被表示为字符串,例如:
"/cpu:0":机器的CPU。"/device:GPU:0":机器的 GPU(前提是已安装)"/device:GPU:1":机器的第二个GPU,以此类推
如果 TensorFlow 操作同时具有 CPU 和 GPU,则在将操作分配给设备时,将优先选择 GPU 设备。 例如,matmul 有 CPU 和 GPU 实现,在具有设备 cpu:0 和 gpu:0 的系统上,将选择 gpu:0来运行 matmul。
判断使用的设备
通过运行配置 log_device_placement 为 True 的会话,可以判断操作和张量使用的设备:
1 | a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a') |
可以看到 TensorFlow 的操作默认使用 GPU:
1 | Device mapping: |
指定设备
可以指定可用的任何设备进行运算。以指定 CPU 为例,使用 with tf.device('/cpu:0') 包裹对应代码即可:
1 | with tf.device('/cpu:0'): |
从结果可以看到 a 和 b 使用 CPU:
1 | MatMul: (MatMul): /job:localhost/replica:0/task:0/device:GPU:0 |
GPU 内存分配
TensorFlow 默认能够使用 GPU 的全部内存,可以通过配置 per_process_gpu_memory_fraction 来控制内存分配。
以如下为例,对于可用的 GPU,TensorFlow 只分配其内存的 40%:
1 | config = tf.ConfigProto() |
CPU vs GPU
测试一
本节代码摘自
Erik Hallström的TensorFlow - CPU vs GPU。
下列代码示例创建随机矩阵对,并对 CPU 和 GPU 计算运行矩阵乘积耗时进行绘图。
1 | from __future__ import print_function |
可以看到,GPU Nvidia GTX 1060 比 CPU Intel i5-4590 快得多。

测试二
使用 TensorFlow 官方的测试基准 alexnet_benchmark.py ,下载运行即可,测试数值越小表示性能越高。
文档说明中有两个型号 GPU 的测试结果。实测 GPU Nvidia GTX 1060 性能比 Tesla K40c 高,比 Titan X 略低。运行时间在一分钟以内。
1 | Forward pass: |
CPU i7-4790 整个运行时间非常慢,总计半小时,测试数值如下:
1 | 2018-02-06 18:49:48.583154: step 0, duration = 2.378 |
总结
神经网络训练过程均需要计算大量的矩阵乘法,和 CPU 相比,GPU 能够很快地训练深度学习模型。