本文介绍了 MCP 神经元和感知器,以及对应的算法实现。
MCP 神经元和感知器原理
Warren McCullock 和 Walter Pitts 通过研究大脑,于1943年提出了第一个人工智能模型:MCP 神经元。
神经元是涉及化学和电信号处理和传输的大脑中相互联系的神经细胞,如下图所示:
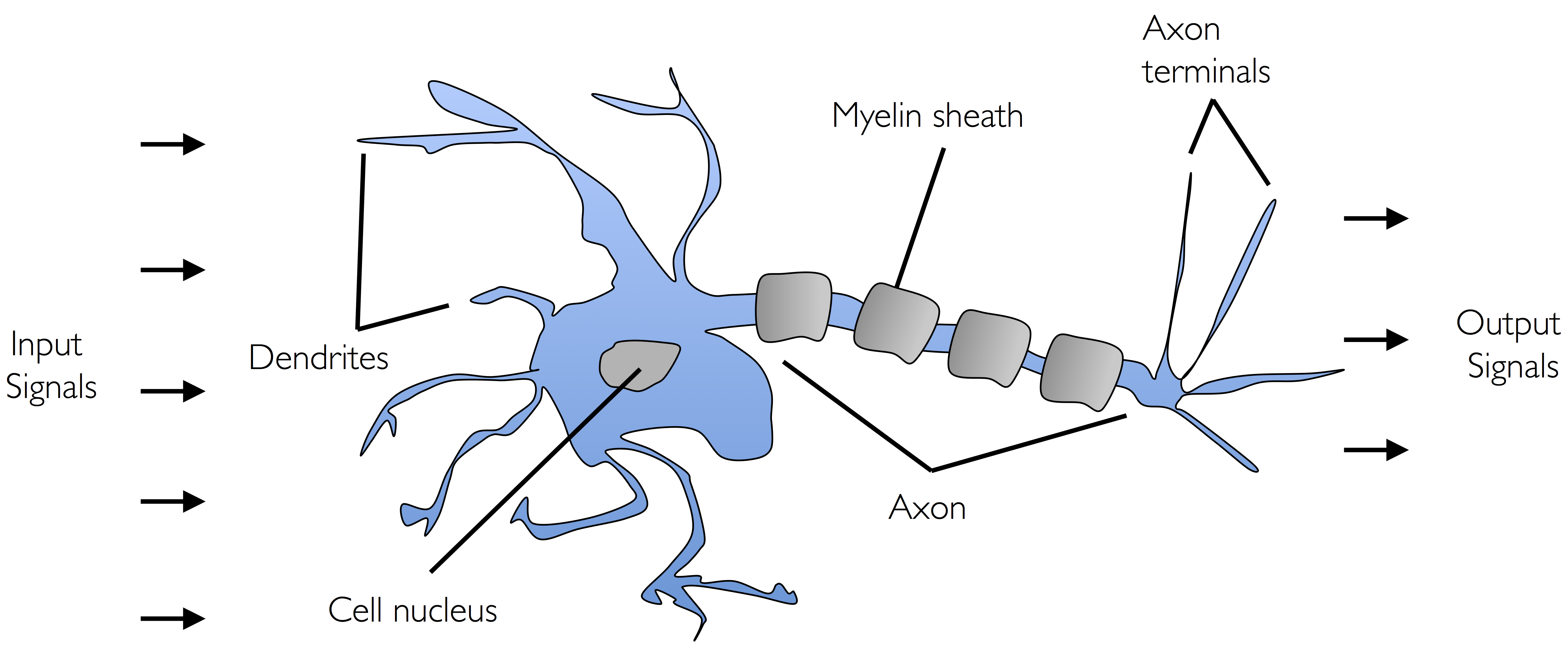
MCP 神经元为具有二进制输出的简单逻辑门。多个信号从树突传入细胞体中,如果累积输入信号超过一定阈值,则从轴突传出输出信号。
Frank Rosenblatt 于 1957 年发表了基于 MCP 神经元模型的感知器学习规则,提出了一种自动学习最佳权重系数的算法,然后与输入特征相乘,从而决定是否触发神经元。这种算法可以用于监督式学习中的分类。
感知器采用输入向量 $x$ 和权重向量 $w$,净输入 $z$ 为这二者的线性组合 ($z = w_1 x_1 + \ldots + w_m x_m$):
$$w = \begin{bmatrix} w_1 \\ w_2 \\ \vdots \\ w_m \\ \end{bmatrix}, x = \begin{bmatrix} x_1 \\ x_2 \\ \vdots \\ x_m \\ \end{bmatrix}$$激活函数采用阶跃函数 $\phi(z)$, $\theta$ 为神经元的触发阈值:
$$\phi(z) = \begin{cases} 1, &\text{if $z \geq \theta$} \\[2ex] -1, &\text{if $z \lt \theta$} \end{cases}$$通过设定 $x_0 = 1$ 和 $w_0 = -\theta$,将 $\theta$ 集成到 $z$ 中,可以让上式更整齐:
$$\begin{align} z = w_0 x_0 + w_1 x_1 + w_2 x_2 + \ldots + w_m x_m = w^T x \end{align}$$ $$\phi(z) = \begin{cases} 1, &\text{if $z \geq 0$} \\[2ex] -1, &\text{if $z \lt 0$} \end{cases}$$下图为通过 $z = w^T x$ 得到 1 或 -1 的激活函数(左子图),以及其用于区分两个线性可分的类(右子图):
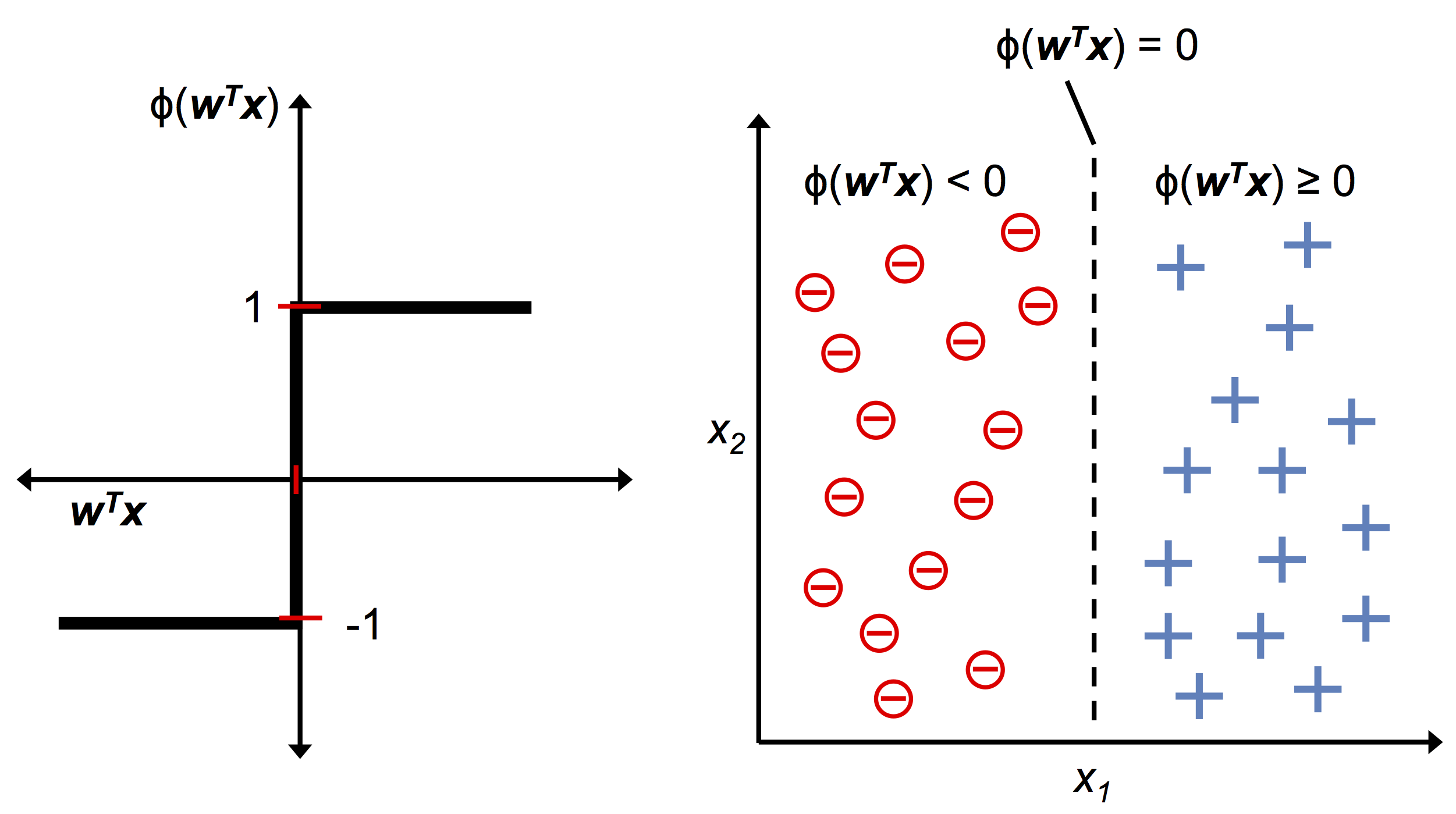
MCP 神经元和 Rosenblatt 阈值感知器模型的思想为简化模拟大脑单个神经元的工作原理,即输入是否达到触发条件。
Rosenblatt 感知器规则非常简单:
- 将权重初始化为 0 或较小的随机数。
- 对于每个训练样本 $x^{(i)}$,执行以下步骤:
- 计算输出值 $\hat y$。
- 更新权重。
权重 $w_j$ 的更新可以表示为:
$$\begin{align} w_j := w_j + \Delta w_j \end{align}$$用于更新权重向量中的第 $j$ 个权重 $\Delta w_j$ 可由感知器学习规则计算得到:
$$\begin{align} \Delta w_j = \eta (y^{(i)} - \hat y^{(i)}) x_j^{(i)} \end{align}$$其中 $\eta$ 是学习率(介于 0 和 1 之间),$y^{(i)}$ 是第 $i$ 次训练的实际类标签,$\hat y^{(i)}$ 是第 $i$ 次训练的预测类标签。
需要注意,权重向量中的所有权重的更新是同时的,更新权重之后才会更新下一次的 $\hat y^{(i)}$。
例如,二维数据的权重更新如下:
$$\begin{align} \Delta w_0 &= \eta (y^{(i)} - output^{(i)}) \\ \Delta w_1 &= \eta (y^{(i)} - output^{(i)}) x_1^{(i)} \\ \Delta w_2 &= \eta (y^{(i)} - output^{(i)}) x_2^{(i)} \end{align}$$在感知器预测正确类标签的情况下,权重保持不变:
$$\begin{align} \Delta w_j &= \eta (-1^{(i)} - -1^{(i)}) x_j^{(i)} = 0 \\ \Delta w_j &= \eta (1^{(i)} - 1^{(i)}) x_j^{(i)} = 0 \end{align}$$在感知器预测错误类标签的情况下,权重朝正确类标签的方向更新:
$$\begin{align} \Delta w_j &= \eta (1^{(i)} - -1^{(i)}) x_j^{(i)} = \eta (2) x_j^{(i)} \\ \Delta w_j &= \eta (-1^{(i)} - 1^{(i)}) x_j^{(i)} = \eta (-2) x_j^{(i)} \end{align}$$为了更好地理解上述表达式中乘数因子 $x_j^{(i)}$ 的作用,这里按照以下条件来举例说明:
$$\begin{align} y^{(i)} = 1, \hat y^{(i)} = -1, \eta = 1 \end{align}$$如果有样本 $x_j^{(i)} = 0.5$,但是被错误分类为 -1,对应的 $\Delta w_j$ 为:
$$\begin{align} \Delta w_j^{(i)} &= 1 \times (1 - (-1)) \times 0.5 = 1 \\ \end{align}$$如果有另外一个样本为 $x_j^{(i)} = 2$,但是被错误分类为 -1,会产生更大的 $\Delta w_j$,以便下次能正确分类:
$$\begin{align} \Delta w_j^{(i)} &= 1 \times (1 - (-1)) \times 2 = 4 \\ \end{align}$$注意,感知器只有在类线性可分且学习率足够小才能收敛。如果类之间不是线性可分的,需要设置最大训练次数或者设置可容忍的错误分类数量,否则感知器会一直更新权重:
下图简单描述了感知器的原理:
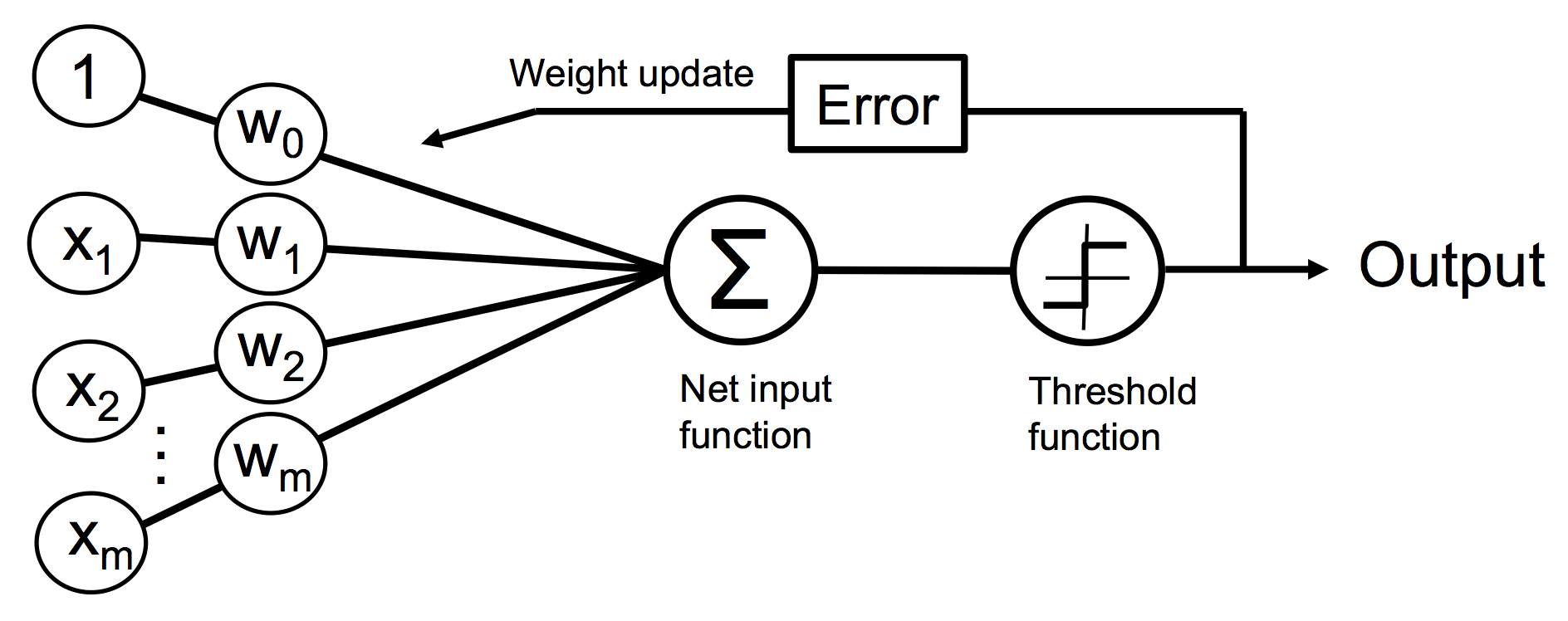
在输入阶段,感知器接收样本 $x$ 的输入并和权重 $w$ 来计算净输入,然后将净输入传递到激活函数(这里采用单位阶跃函数),该函数生成输出预测类标签 -1 或 +1。在学习阶段,该输出用于计算预测误差并更新权重。
Rosenblatt 感知器的 Python 实现
下面代码中,采用了面向对象的方法,定义感知器为 Python 类。
1 | import numpy as np |
通过上述实现,可以通过指定学习速率 eta 和训练次数 n_iter 来初始化感知器对象。fit 方法可以初始化一个全 0 权重向量 self.w_,包含权重 $w_0$ ~ $w_m$ 。
在权重初始化后,使用感知器的学习规则更新权重。fit 传入已知样本和对应标签,用于训练阶段得到算法参数;predict用于预测任何样本(通常使用未知样本以观察算法性能)的对应标签,用于验证阶段。
另外,这里定义了错误分类的样本数目 self.errors_,以观察算法在每次训练后的表现。
基于 Iris 数据集的感知器模型训练
读取 Iris 数据集
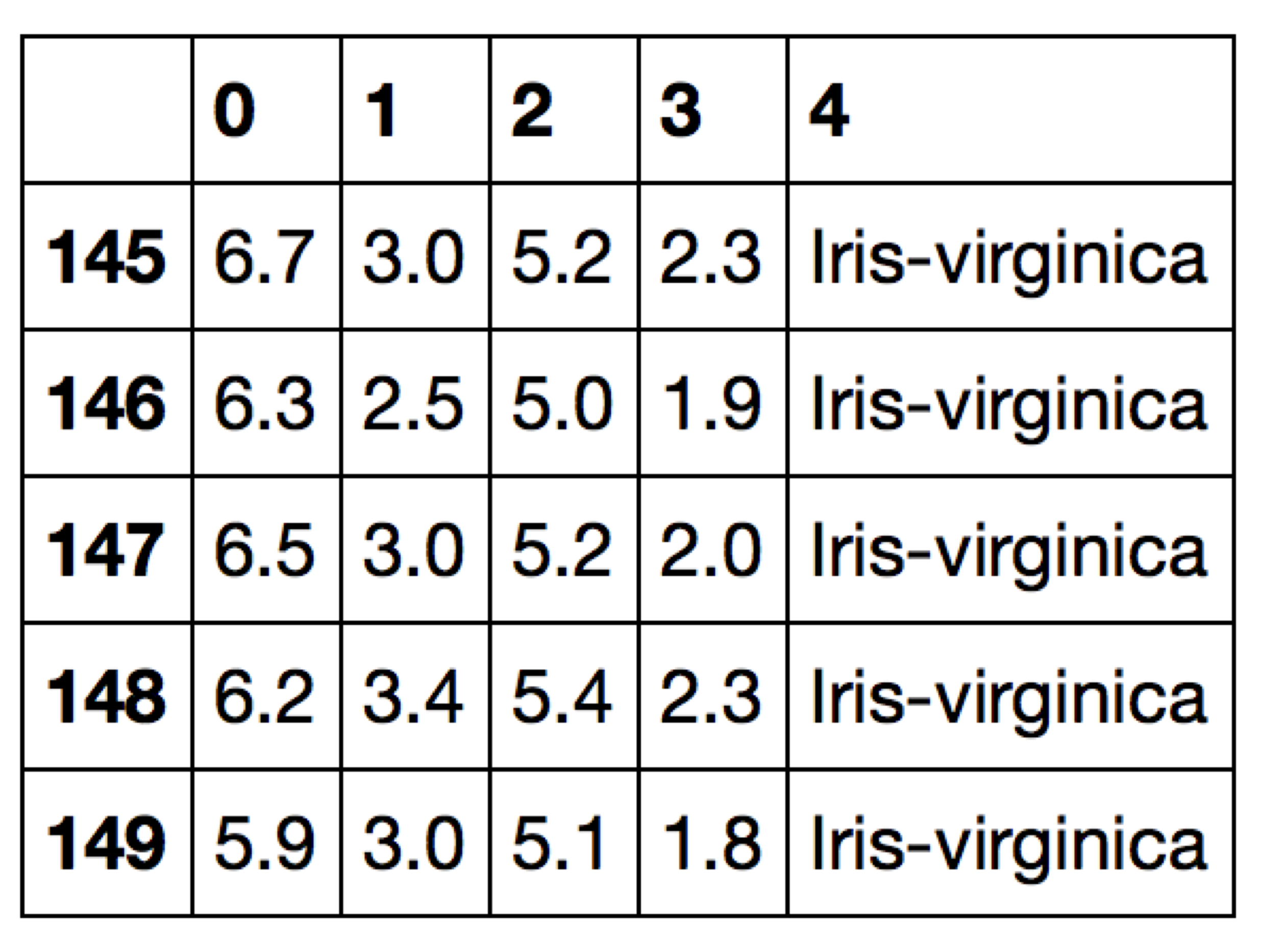
Iris 数据集 可以看做矩阵 $R^{150 \times 4}$,具有 150 个样本,4 个特征(花萼长度 sepal length、花萼宽度 sepal width、花瓣长度 petal length、花瓣宽度 petal width),可分成 3 个分类(山鸢尾 Setosa、变色鸢尾 Versicolor、维吉尼亚鸢尾 Verginica)。
从 UCI Machine Learning Repository 读取 Iris 数据集,并打印最后五行:
1 | import pandas as pd |
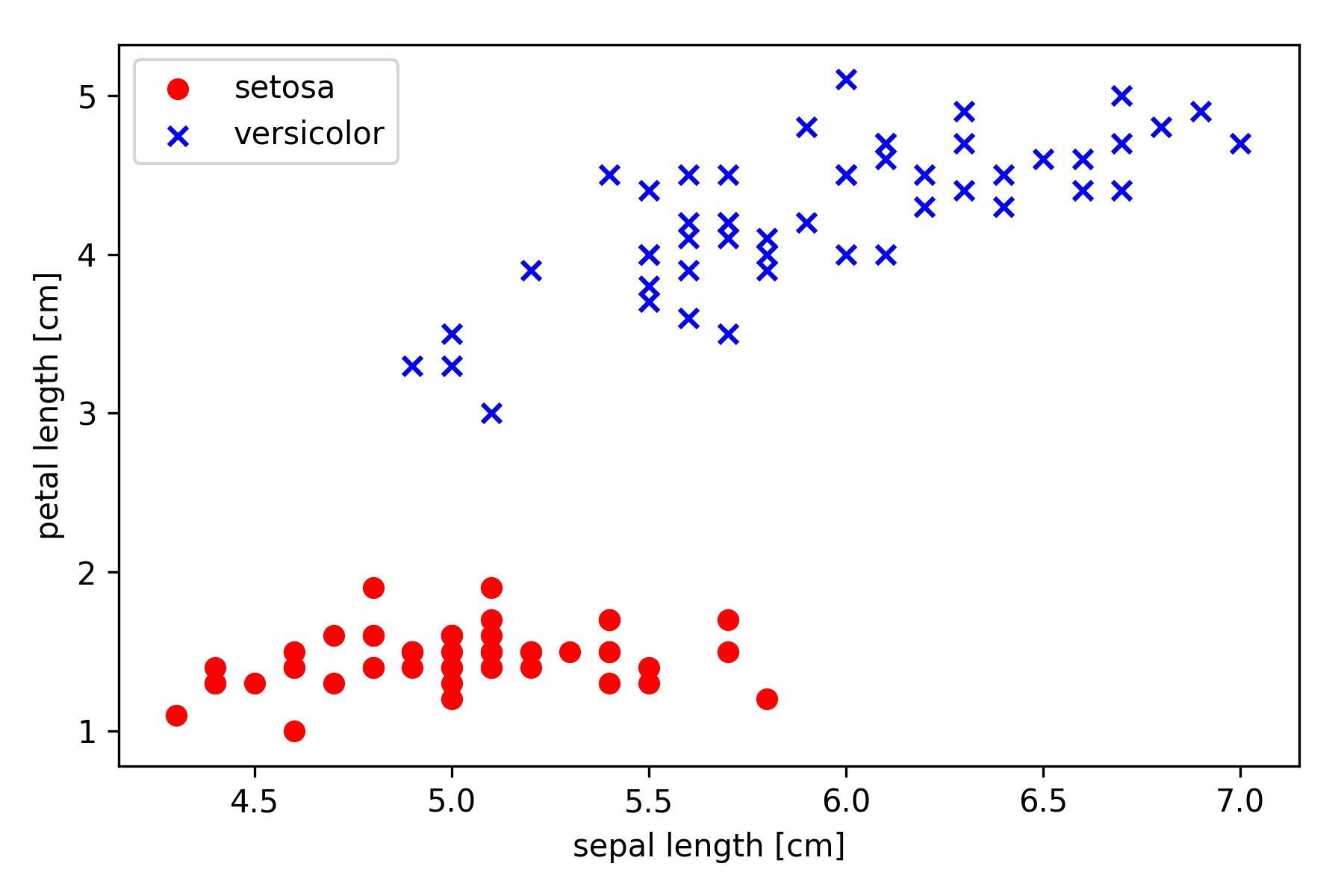
Iris 数据子集绘图
为了简单演示训练流程,我们只挑选 Sepal Length 和 Petal Length 这两个特征,另外只挑选 Setosa 和 Versicolor 这两类。
我们提取前 100 个样本的类标签(依次对应50个 Setosa 和50个 Versicolor),并将类标签转换为整数类标签-1(Setosa) 和 1(Versicolor),用 pandas.DataFrame 表示。
然后提取这 100 个样本的第一个特征列 Sepal Length 和第三个特征列 Petal Length,将它们分配给特征矩阵 X并通过二维散点图可视化:
1 | import pandas as pd |
感知器模型训练
接下来在提取的 Iris 数据子集上训练我们的感知器算法,同时,我们将绘制每次训练后的分类错误以检查算法是否收敛,并找到分离两个花类的决策边界:
1 | ppn = Perceptron(eta=0.1, n_iter=10) |
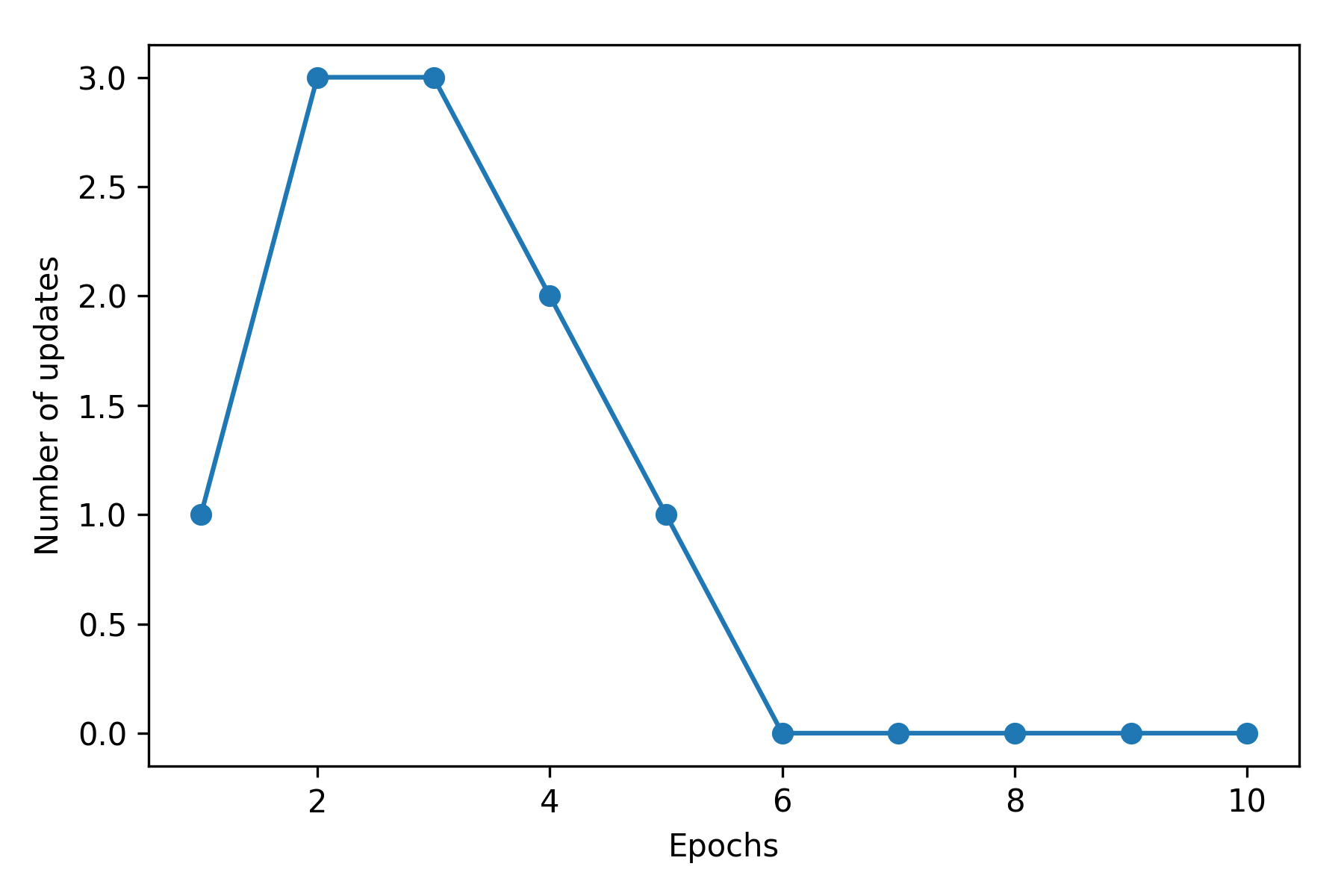
从上图可以观察到在六次训练后,样本错误分类数目为 0,算法得到收敛。
决策边界绘图
定义决策边界绘图函数如下:
1 | from matplotlib.colors import ListedColormap |
对上一节中的样本进行绘图:
1 | plot_decision_regions(X, y, classifier=ppn) |
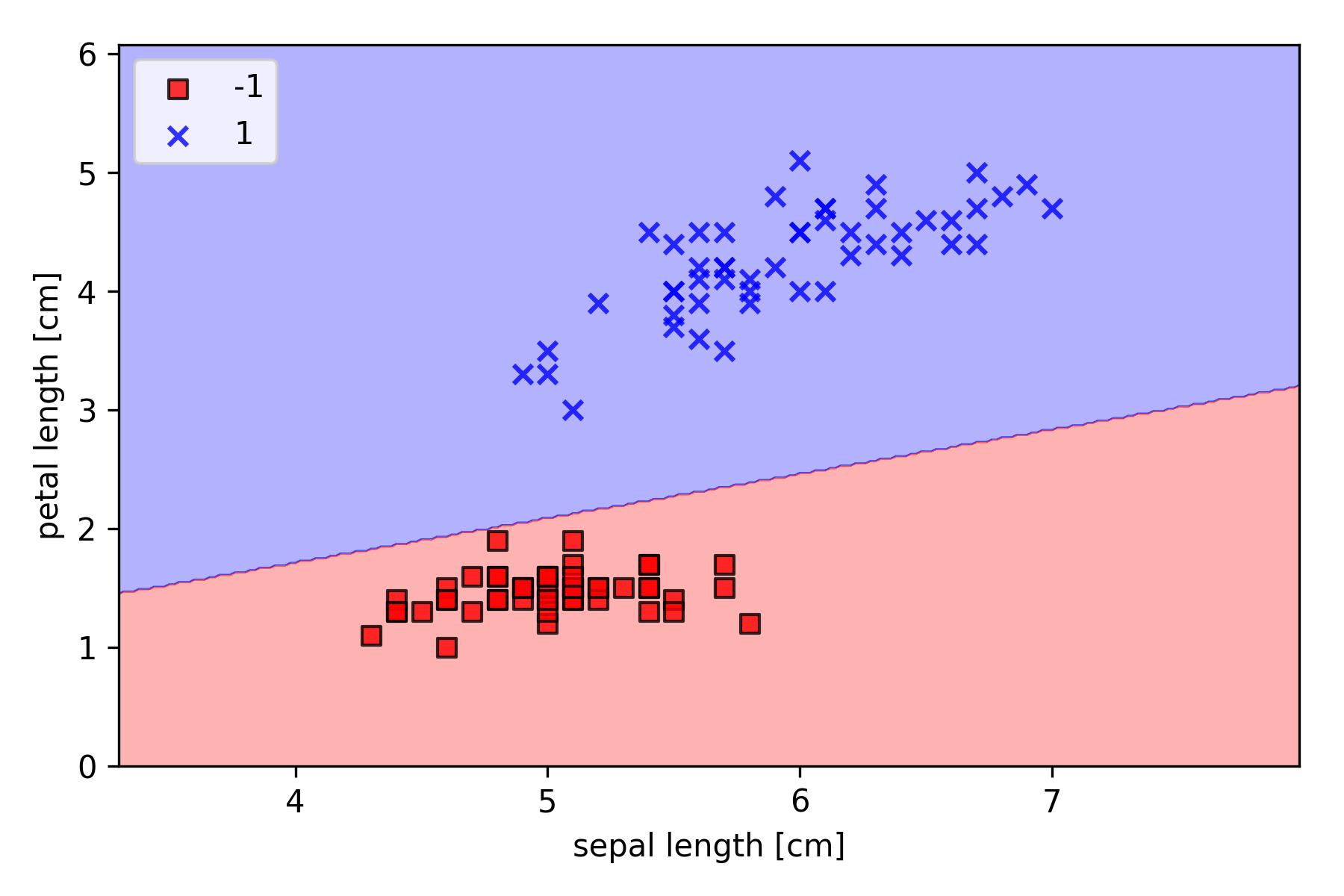
通过学习,感知器生成了将 Iris 训练子集完全分类的决策边界。
虽然本例中感知器能够完全分类两种花卉,但收敛仍是感知器最重要的问题之一。如果两个类线性可分,感知器算法就能够收敛。然而对于无法线性可分的类,除非我们手动设置最大训练次数,否则权重永远不会停止更新。