本文介绍懒惰学习的一个典型示例:K-近邻(K-Nearest Neighbors, KNN)算法。
之所以称为懒惰,是因为它不从训练样本中学习判别函数,而是在记住已有的样本数据集的基础上对新样本进行分类。
算法思想
机器学习算法可以被分为两大类,参数模型和变参模型:
参数模型:学习时更新参数然后将其用于预测,如感知器、逻辑回归、线性 SVM
变参模型:参数不固定,如决策树/随机森林、使用核技巧的 SVM
KNN 属于变参模型的一个子类:基于实例的学习(instance-based learning),在训练过程中记住整个训练集。
懒惰学习是基于实例的学习的特例,在整个学习过程中不涉及损失函数的概念。
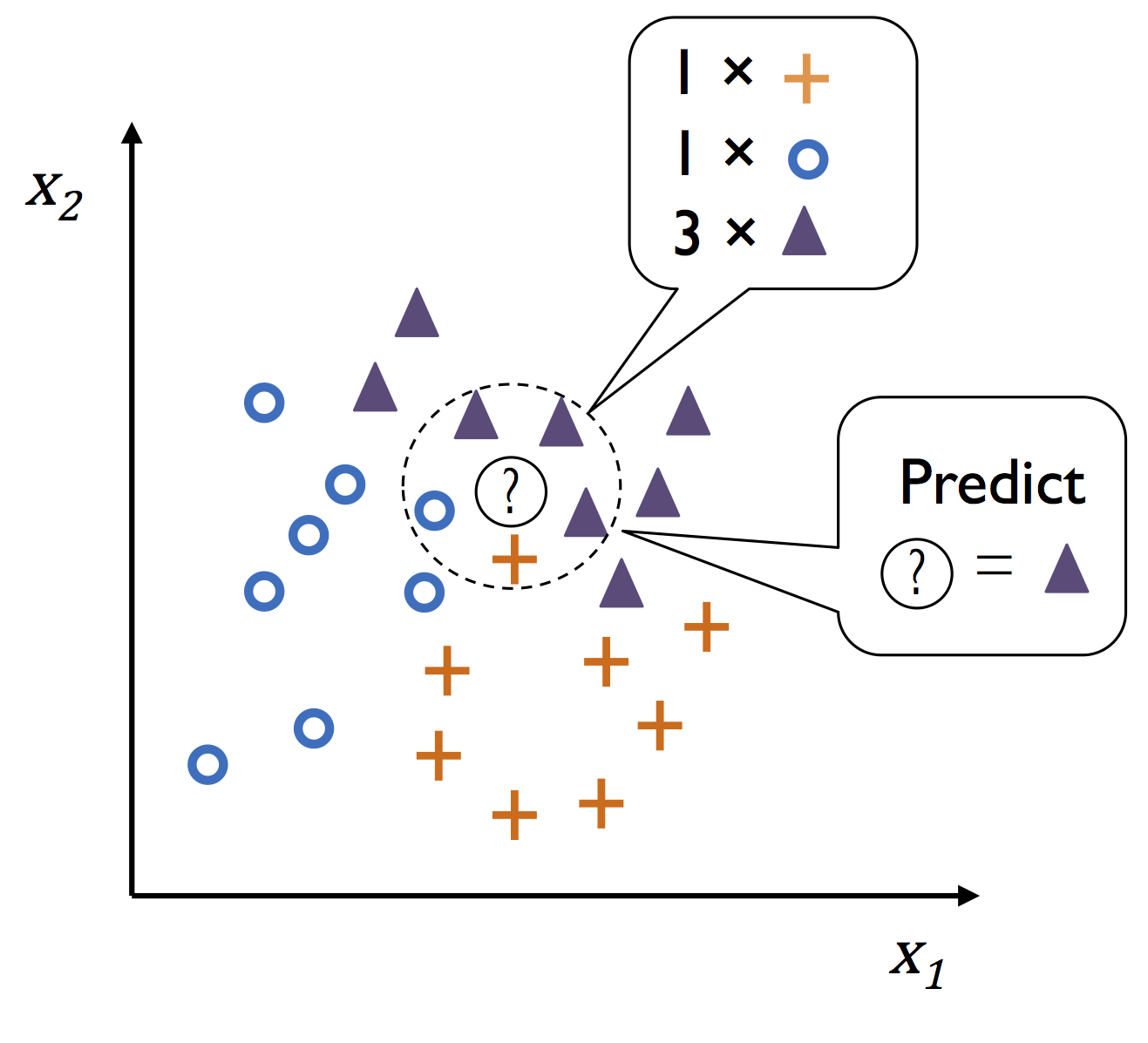
KNN 算法非常简单,步骤及图示如下:
- 确定 $k$ 的大小和距离度量。
- 对于测试集中的一个样本,找到训练集中和它最近的 $k$ 个样本。
- 将这 $k$ 个样本的投票结果作为测试样本的类别。
算法实现
以 Iris 数据集为例,基于 Scikit-learn 的实现如下(设置 $k = 5$):
1 | from sklearn.neighbors import KNeighborsClassifier |
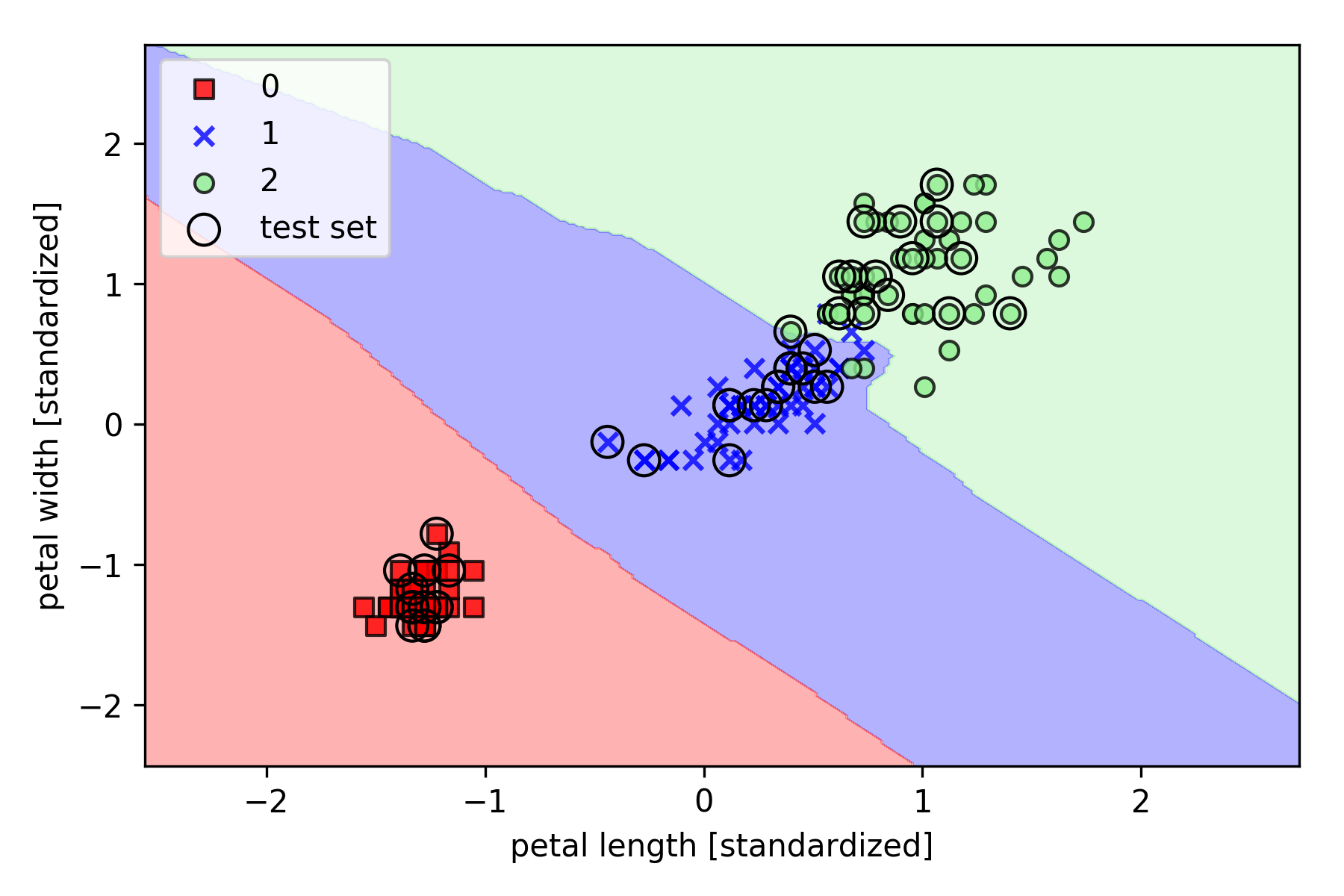
$k$ 的选择对于 KNN 模型来说至关重要,另外一个重要参数为距离度量。
上述代码使用的是 minkowski 距离:
若 $p=2$,则代表欧几里得距离;若 $p=1$,则代表曼哈顿距离。
算法的维度问题
如果特征空间维度非常高,空间中最相似的两个点也可能距离很远,KNN 算法很容易过拟合。
在这种情况下,建议通过特征选择和降维等方法来避免维度问题。