Scikit-learn 的名字源于 SciKit(SciPy Toolkit),即 SciPy 的第三方扩展工具包。经过历年的发展,Scikit-learn 已成为最流行的机器学习库之一。
本文以 Iris 数据集的分类为例,对其进行简介。
如 官方网站 所介绍,以下是 scikit-learn 的特征:
- 简单高效的数据挖掘和数据分析工具
- 可供任何人使用,可在任何环境中重复使用
- 基于 NumPy, SciPy, 以及 matplotlib
- 开放源码,可用作商业用途(需遵循BSD许可证)
关于 scikit-learn 的安装,请参照 这份文档 。
数据导入
从 scikit-learn 加载 Iris 数据集,其中第三列表示花瓣长度 petal length,第四列表示花瓣宽度 petal width。
这些类已经转换为整数标签,其中 0 = 山鸢尾 Iris-Setosa,1 = 变色鸢尾 Iris-Versicolor,2 = 维吉尼亚鸢尾 Iris-Verginica。
1 | from sklearn import datasets |
预处理
通过函数 sklearn.model_selection.train_test_split 将 150 个数据集分为 70% 的训练集和 30% 的测试集:
1 | from sklearn.model_selection import train_test_split |
这里 stratify=y 表示按照标签值将数据集划分,划分后训练集和测试集的标签具有相同的比例,可以用 np.bincount 打印其中每类标签的个数:
1 | print('Labels counts in y:', np.bincount(y)) # output: Labels counts in y: [50 50 50] |
通过函数 sklearn.preprocessing.StandardScaler 对特征进行标准化:
1 | from sklearn.preprocessing import StandardScaler |
模型训练
使用神经元模型 sklearn.linear_model.Perceptron ,对训练集进行训练 fit:
1 | from sklearn.linear_model import Perceptron |
模型评估
训练完成后,对测试集进行预测 predict,并打印出其中错误预测的样本数量:
1 | y_pred = ppn.predict(X_test_std) |
训练准确率可以通过 sklearn.metrics.accuracy_score 得到:
1 | from sklearn.metrics import accuracy_score |
scikit-learn 中的每种分类函数都有计算准确率的方法 score ,执行时会计算 accuracy_score 并返回,输出结果相同:
1 | print('Accuracy: %.2f' % ppn.score(X_test_std, y_test)) # output: Accuracy: 0.93 |
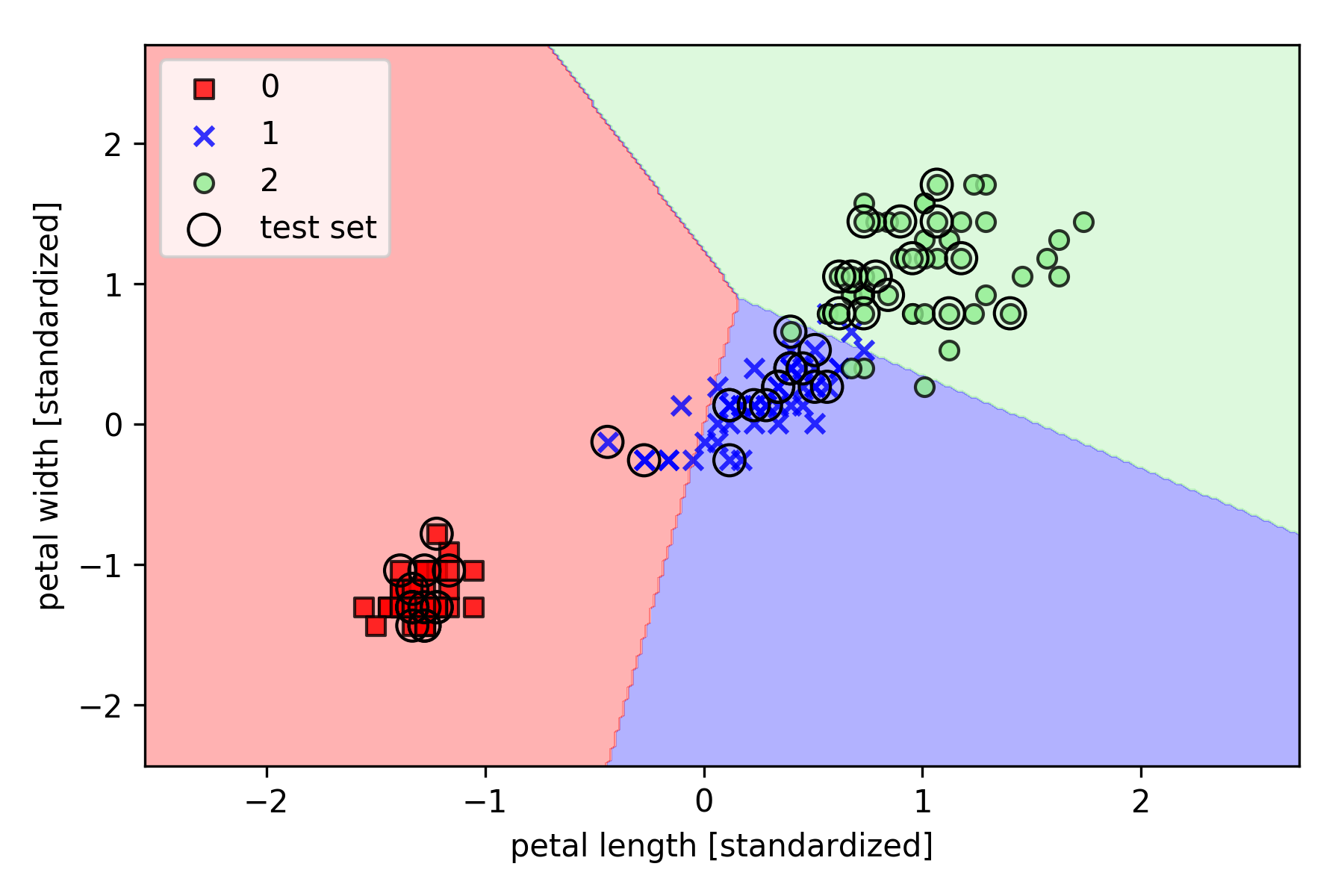
绘制分类边界
对算法训练过程进行绘图:
1 | from matplotlib.colors import ListedColormap |
绘制边界如下,其中测试集用黑色圆圈标出: